All Publications
Publication
2025
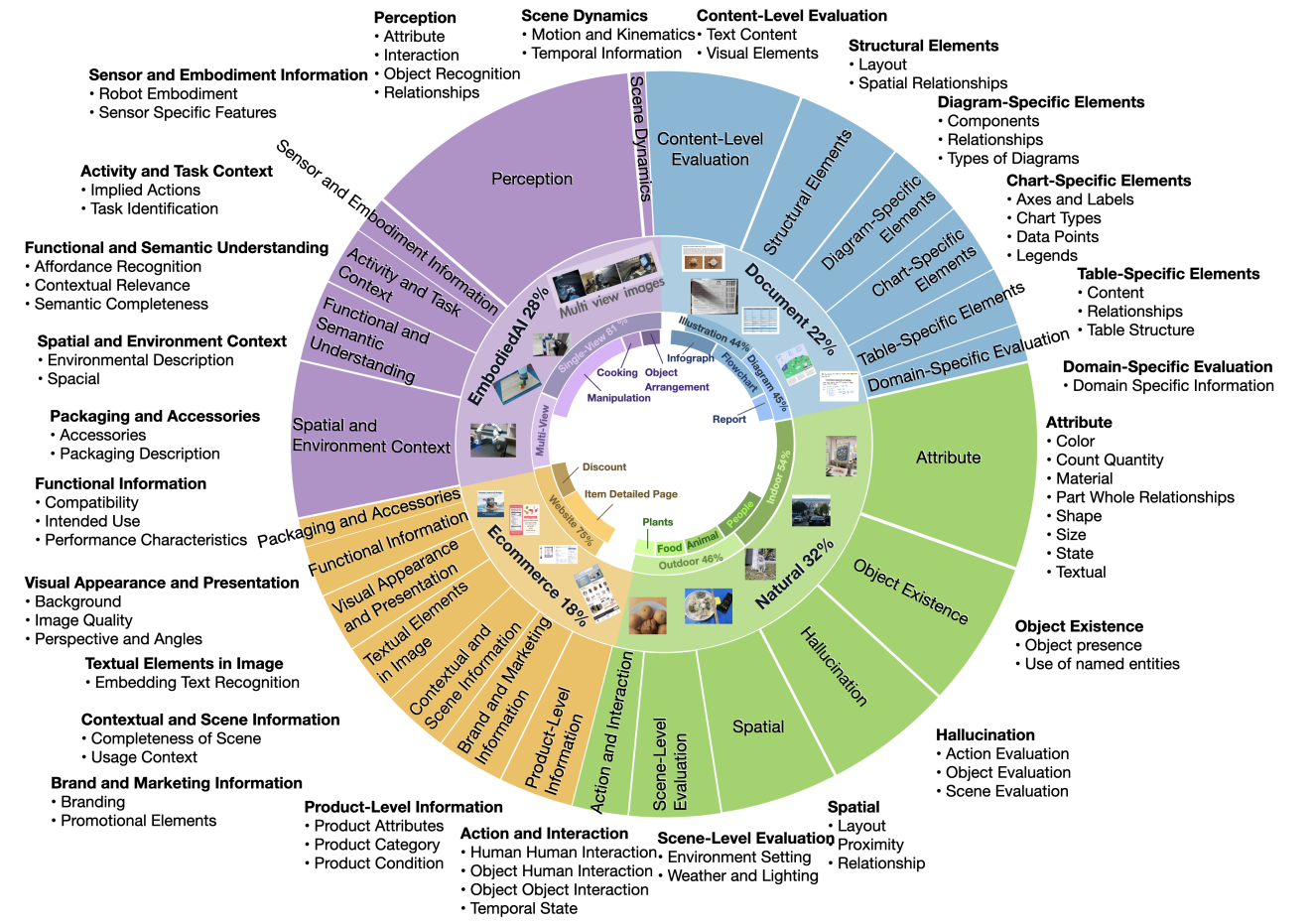
CaptionQA: Is Your Caption as Useful as the Image Itself?
CaptionQA is a utility-based benchmark evaluating caption quality across 4 domains with 33,027 annotated questions, revealing up to 32% gap between image and caption utility in state-of-the-art MLLMs.
Read more
Publication
2025
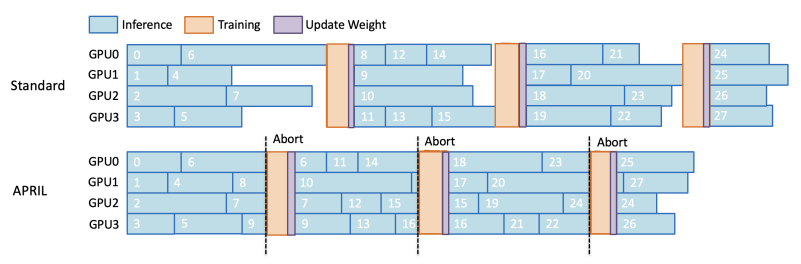
APRIL: Active Partial Rollouts in Reinforcement Learning to Tame Long-tail Generation
APRIL mitigates long-tail inefficiency in RL training by over-provisioning rollout requests, recycling incomplete responses, and reducing GPU idle time — achieving up to 44% throughput improvement and 8% higher accuracy across GRPO, DAPO, and GSPO algorithms.
Read more
Publication
NeurIPS 2025 MATH-AI Workshop
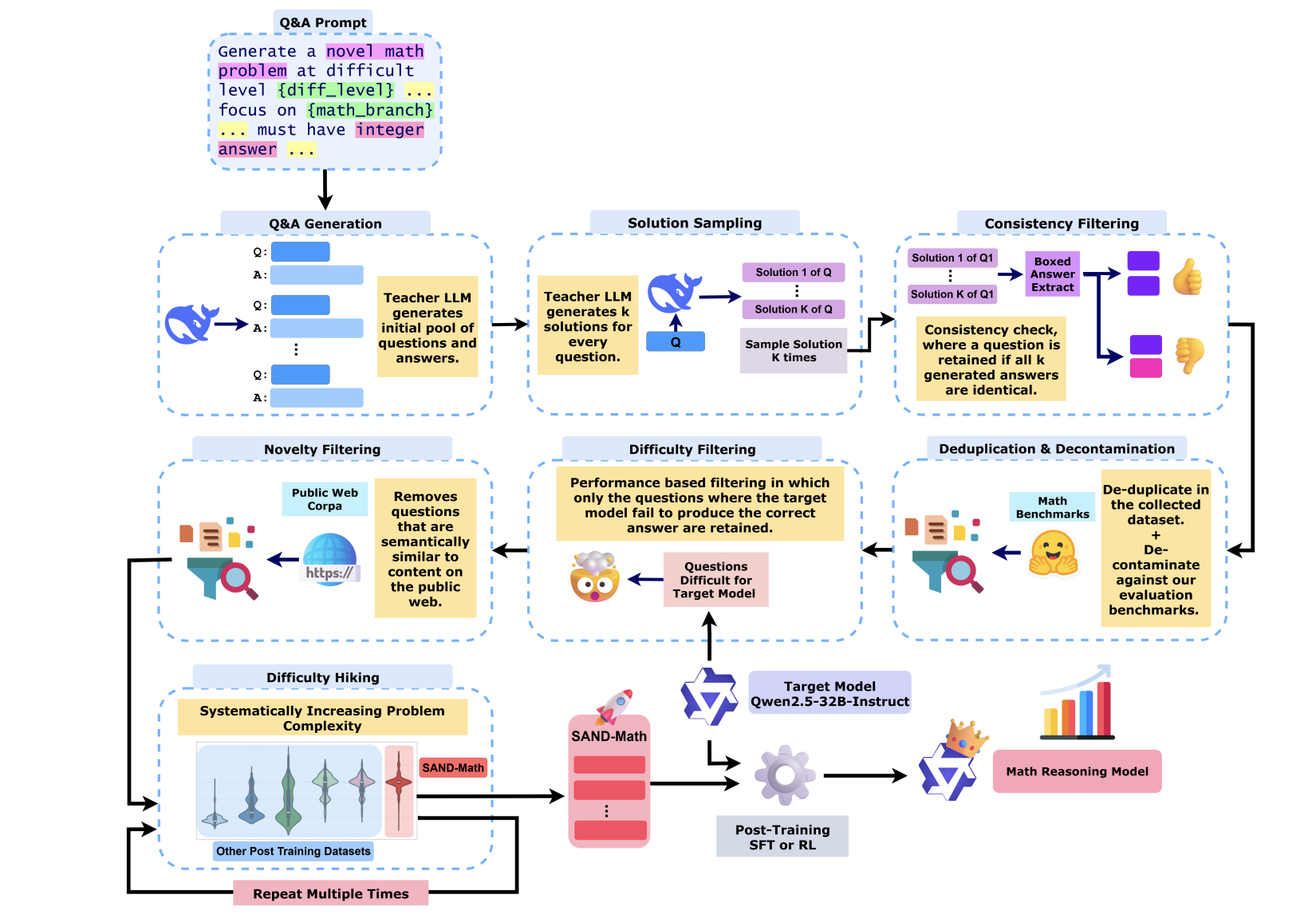
SAND-Math: Using LLMs to Generate Novel, Difficult and Useful Mathematics Questions and Answers
SAND-Math, a scalable pipeline that generates and enhances challenging math problems, enabling LLMs to achieve state-of-the-art results on difficult mathematical reasoning benchmarks like AIME25.
Read more
Publication
EMNLP 2025 Main Conference
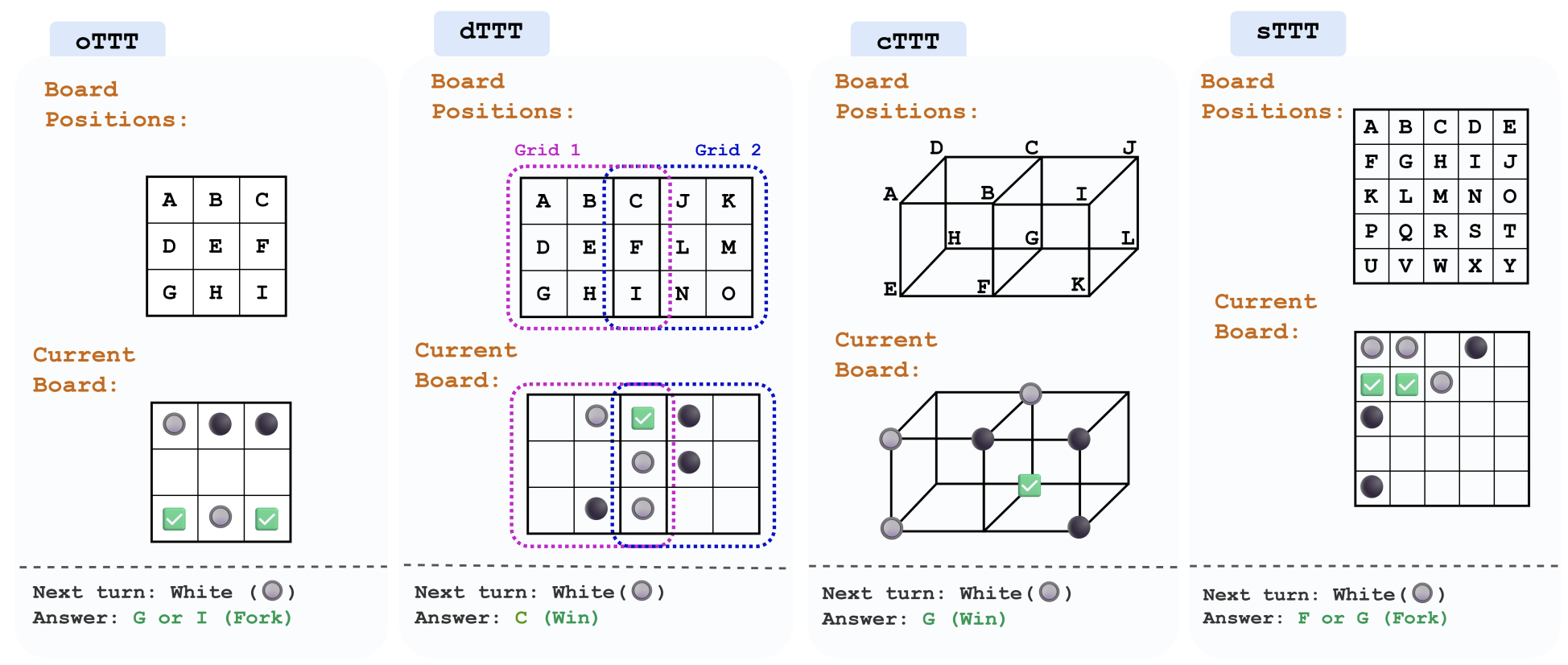
TTT-Bench: A Benchmark for Evaluating Reasoning Ability with Simple and Novel Tic-Tac-Toe-style Games
TTT-Bench uncovers the hidden blind spots of today’s smartest AI, challenging them with simple, human-intuitive games — and showing that even the best models often fail where humans excel effortlessly.
Read more
Publication
ACL 2025 Industry Track (Oral)
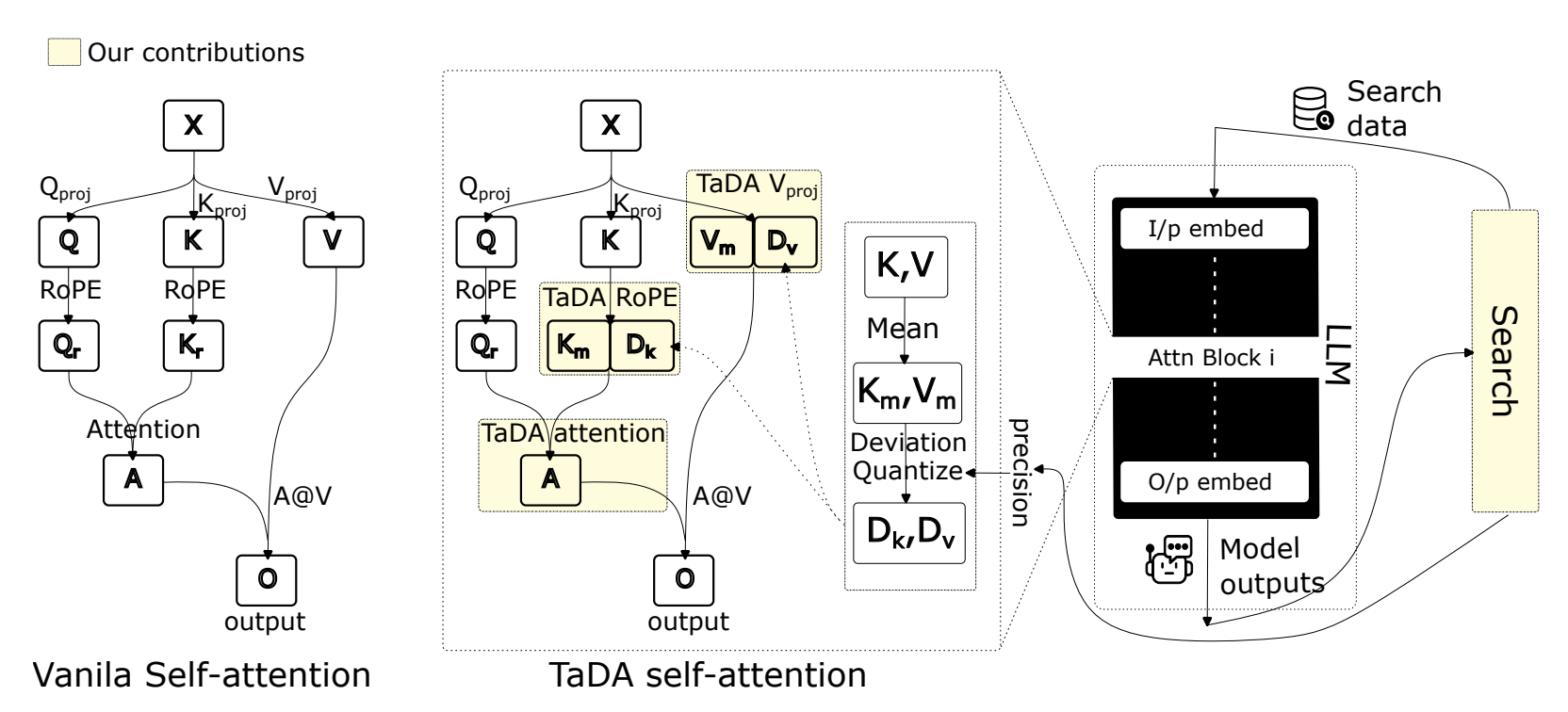
TaDA: Training-free recipe for Decoding with Adaptive KV Cache Compression and Mean-centering
TaDA slashes KV cache memory usage by over 70% without sacrificing accuracy — enabling longer, smarter, and more scalable LLM inference with zero retraining.
Read more
Publication
NeurIPS 2025 (Spotlight)
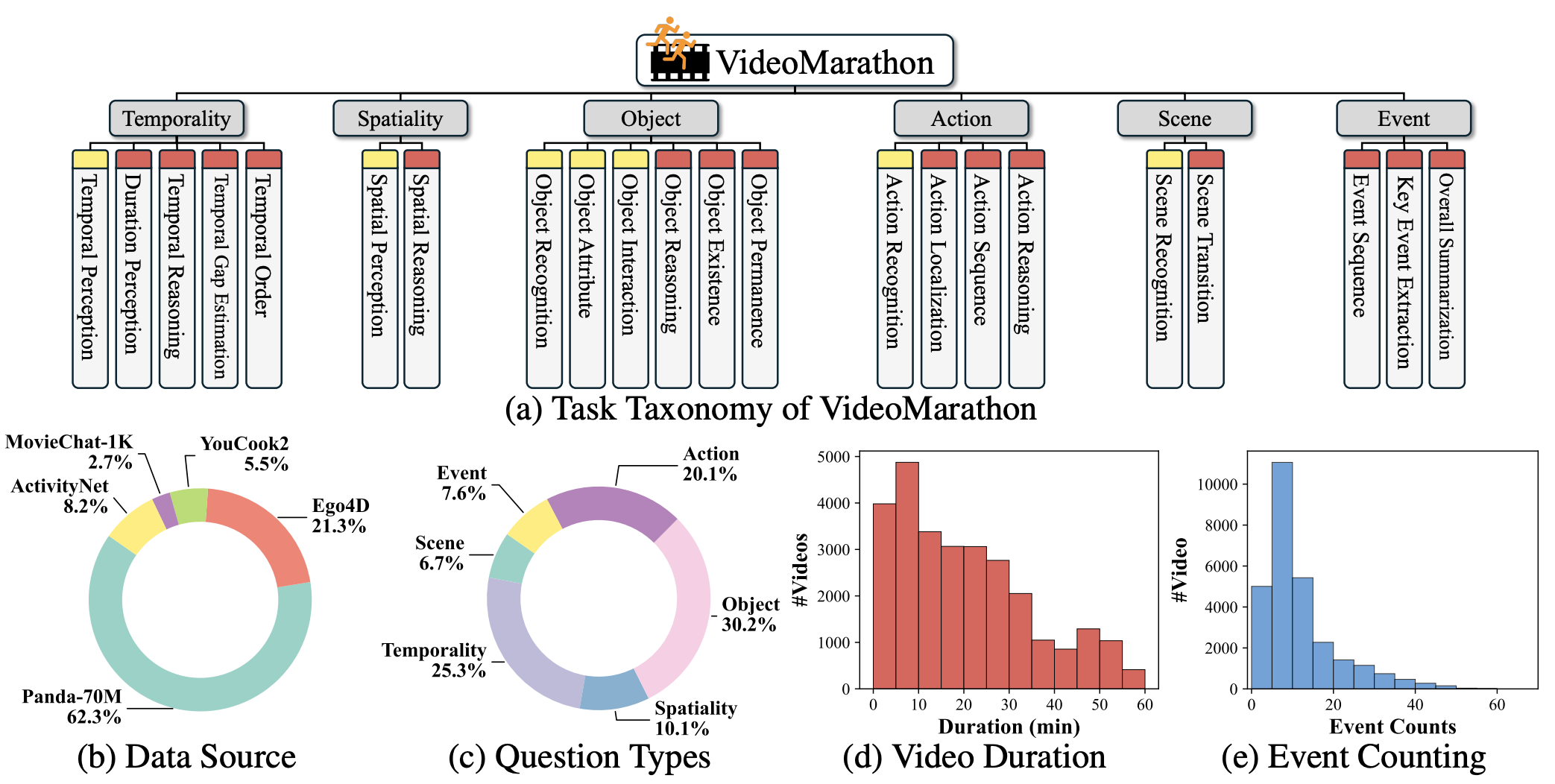
Unleashing Hour-Scale Video Training for Long Video-Language Understanding
“Hour-LLaVA, built on the new VideoMarathon dataset, enables efficient training and inference on hour-long videos and achieves SOTA on long-form video-language tasks.”
Read more
Publication
ACL 2025 Main Conference
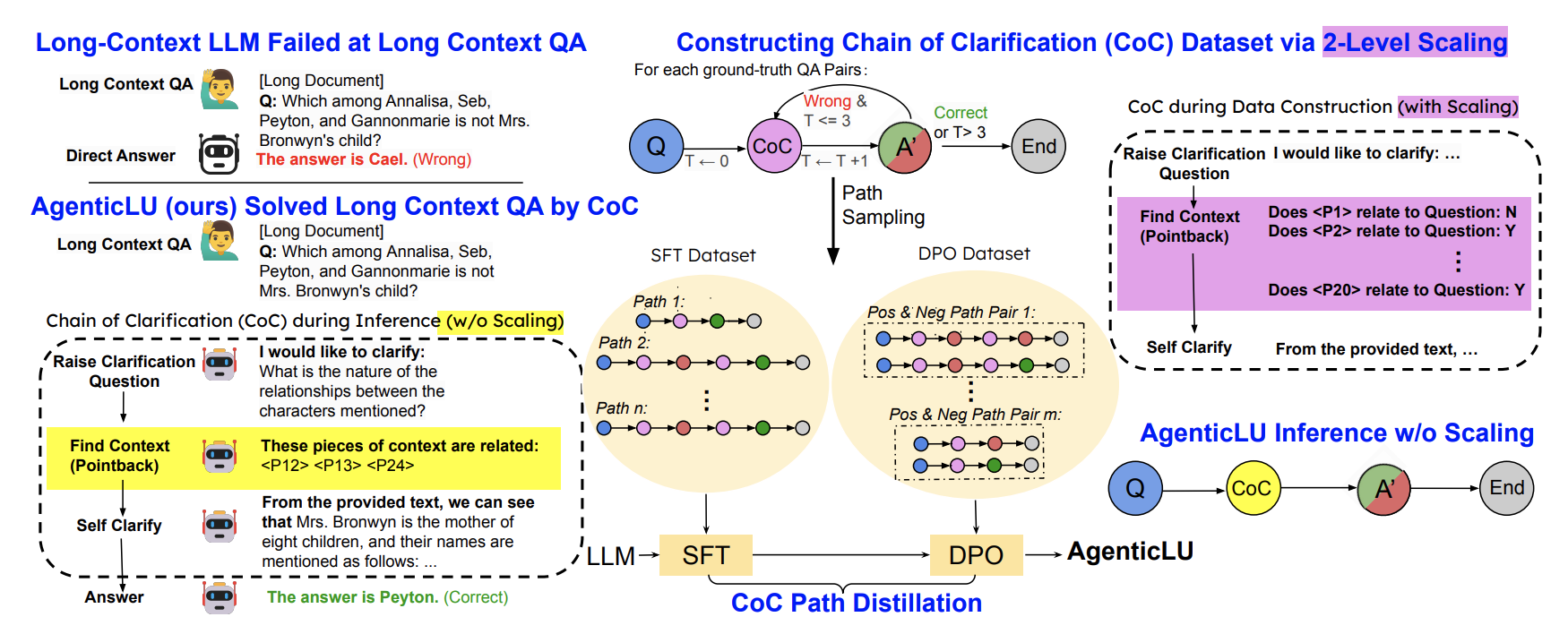
Self-Taught Agentic Long Context Understanding
AgenticLU unlocks the full potential of LLMs on long-context queries, combining self-driven clarifications and smart context retrieval to deliver robust, scalable, and state-of-the-art reasoning.
Read more

Publication
2025
MOVi: Training-free Text-conditioned Multi-Object Video Generation
MOVi, a training-free framework for multi-object T2V generation with LLM-guided trajectory control and attention refinement, achieving 42% better motion and object accuracy.
Read more
Publication
ICCV 2025 Gen4AVC Workshop
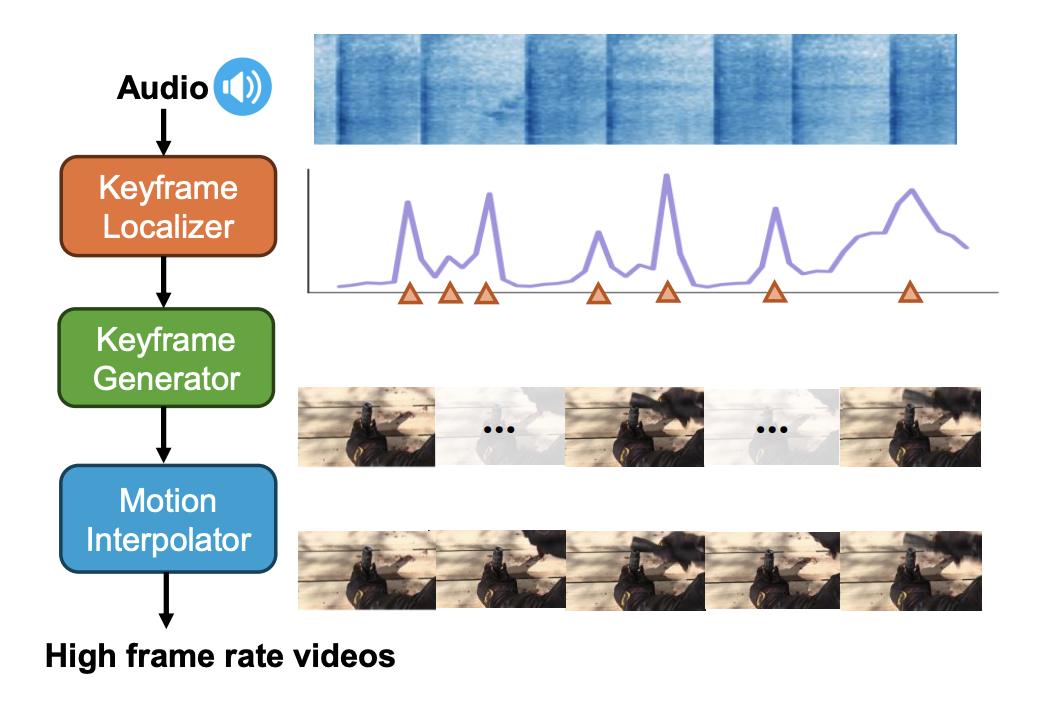
KeyVID: Keyframe-Aware Video Diffusion for Audio-Synchronized Visual Animation
KeyVID leverages audio-aware keyframes and motion interpolation to generate synchronized, high-quality audio-to-visual animations with improved dynamic motion handling.
Read more
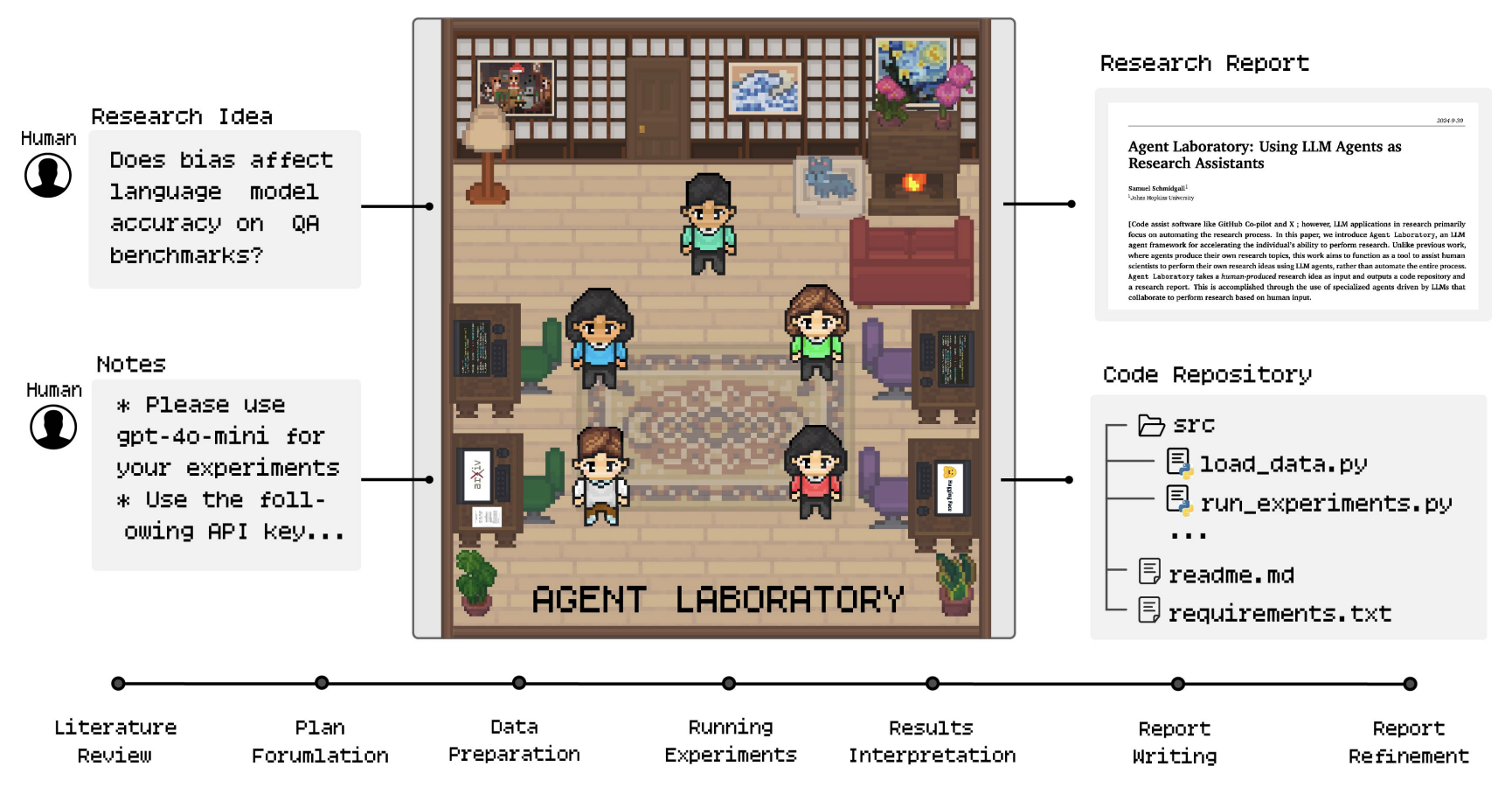
Publication
EMNLP 2025 Findings
Agent Laboratory: Using LLM Agents as Research Assistants
Agent Laboratory revolutionizes scientific discovery by automating the entire research workflow — empowering researchers to focus on ideas, not grunt work, with up to 84% lower cost and state-of-the-art results.
Read more

Publication
CVPR 2025
SoftVQ-VAE: Efficient 1-Dimensional Continuous Tokenizer
SoftVQ-VAE unlocks fast, efficient, and high-quality image generation with ultra-compact tokenization — delivering up to 55× faster inference and competitive FID, all with fewer training iterations.
Read more